DynamoDB Serverless Data
Adding NoSQL data persistence to AWS Lambda and API Gateway

Now that we have a basic API Gateway endpoint and Lambda function, the next meaningful step is to save the data posted to the API. Keeping with the AWS serverless theme, in this article we will add persistence with the help of DynamoDB. We will also keep things automated by continuing to utilize the AWS Serverless Application Model (SAM).
This article expands on my previous posting, Serverless Cloud API Development. You may find it beneficial to start there, particularly if these topics are new to you.
Source Code
You can find the source code for this project in my GitHub repo.
Expanding The Data Model
DynamoDB is the flagship serverless NoSQL database offering from AWS. Whereas in a relational database environment it is common to begin with a database as top-level container, in DynamoDB we will focus simply on a Table. DynamoDB tables are schemaless, which means they allow different attributes to exist on different items stored in a table. However, a primary key is required when defining a table. This brings up the first change needed to the data model in this project.
The RideLog data class previously defined did not include an identifier for the user who owns the data item, and this is certainly needed. Since the demo application allows a user to save basic ride log data, it makes sense to define a userId field on the data class.
It is important to design a DynamoDB table to support the data access patterns required by your application. This begins with careful consideration of the primary key for the table. We can imagine that an application for our Ride Log data will be accessed by a particular user, and this led to defining the userId field in the Java class and annotating the getter method with @DynamoDbPartitionKey. In addition, it is reasonable to expect a listing of multiple Ride Log items will be displayed in chronological order, and this fits well with annotating the startDateTime getter method with @DynamoDbSortKey. This means the primary key will be a composite primary key, since it uses both a partition key and a sort key.
Note that these annotations, highlighted in the code snippet below, come from the DynamoDB Enhanced Client in the AWS SDK for Java, which we obtain by adding the dynamodb-enhanced Maven dependency to the project POM file. This library provides a simple way to map our data class to the DynamoDB table we are creating.
If you are new to DynamoDB, you will likely find it helpful to review the core components, including the explanation of primary key options for a table.
Revised Data Class
package dev.ericrybarczyk.ridelog;
import com.fasterxml.jackson.databind.annotation.JsonDeserialize;
import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import software.amazon.awssdk.enhanced.dynamodb.mapper.annotations.DynamoDbBean;
import software.amazon.awssdk.enhanced.dynamodb.mapper.annotations.DynamoDbPartitionKey;
import software.amazon.awssdk.enhanced.dynamodb.mapper.annotations.DynamoDbSortKey;
import java.time.LocalDateTime;
@DynamoDbBean
public class RideLog {
private String userId;
private LocalDateTime startDateTime;
private LocalDateTime endDateTime;
private double startLatitude;
private double startLongitude;
private double endLatitude;
private double endLongitude;
private double distance;
private String rideTitle;
private String rideLocation;
@DynamoDbPartitionKey
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
@DynamoDbSortKey
@JsonSerialize(using = LocalDateTimeSerializer.class)
public LocalDateTime getStartDateTime() {
return startDateTime;
}
@JsonDeserialize(using = LocalDateTimeDeserializer.class)
public void setStartDateTime(LocalDateTime startDateTime) {
this.startDateTime = startDateTime;
}
// remaining getters and setters omitted for brevity
}Defining the DynamoDB Table
Now that we have our data items defined, we need a DynamoDB table in which to store them. This is defined as a Resource in the SAM template along with the Lambda function we defined previously, by adding the YAML shown below.
# add this to template.yaml, under the Resources node
RideLogTable:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
- AttributeName: "userId"
AttributeType: "S"
- AttributeName: "startDateTime"
AttributeType: "S"
KeySchema:
- AttributeName: "userId"
KeyType: "HASH"
- AttributeName: "startDateTime"
KeyType: "RANGE"
ProvisionedThroughput:
ReadCapacityUnits: "5"
WriteCapacityUnits: "5"
TableName: "RideLogs"As mentioned, DynamoDB tables are schemaless, so we do not define all the attributes of the data items when defining the table. Only the primary key fields are defined. If we were defining any secondary indexes on the table, we would also include these attributes in the table definition. Beyond that, attempting to define additional attributes will cause an error during deployment.
When defining the KeySchema property, note the values for KeyType are HASH and RANGE. These values correspond to the Partition Key and the Sort Key, respectively.
Capacity Planning
When defining a DynamoDB table, we also need to determine the expected read and write capacity required. This is essentially a measure of the I/O our application will perform on the table, and has direct implications for performance characteristics as well as our costs for the data storage and access.
Sample Data Item
{
"userId": "rider@example.com",
"startDateTime": "2022-02-13T12:09:42.032367",
"endDateTime": "2022-02-13T14:09:42.03818",
"startLatitude": 36.477759,
"startLongitude": -94.236827,
"endLatitude": 36.494762,
"endLongitude": -94.206545,
"distance": 21.8,
"rideTitle": "Beautiful Ride",
"rideLocation": "Back 40 Trail"
}The sample data item above uses less than 300 bytes of storage, and even allowing for somewhat longer string values for some attributes, this falls well under the 4 KB read unit size and 1 KB write unit size provided by DynamoDB.
It is worth noting that field names are part of the storage size for items in DynamoDB. This means using short field names can be worthwhile in terms of both cost and performance. To keep this demo code modest in scope, we will use the field names as shown, along with a simple setting of 5 Read Capacity Units and 5 Write Capacity Units for the table. This will result in the ability to write up to five of our RideLog data items per second, along with reading up to 10 items per second when using eventually consistent reads, which is the default setting.
A deep analysis of read and write capacity options and the associated costs are beyond the scope of this article, but you can begin your journey with the AWS documentation covering Read/Write Capacity Mode as well as details about Item Sizes and Formats.
Additionally, Dynobase, makers of a professional GUI client for DynamoDB, provides a free online capacity calculator as well as a pricing calculator, both of which can help you understand these topics further.
Revised Lambda Code
Below is the revised Lambda function, which makes use of the DynamoDbEnhancedClient to get a reference to the DynamoDB table we’ve deployed and then save the RideLog instance obtained from the API Gateway request object. The details used in the returned Location HTTP header have also been updated to reflect the composite primary key for the item.
Things like SDK clients should be initialized at the class level whenever possible. The AWS Lambda runtime reuses the class instance for a period of time, so this means the SDK client instance is only initialized once, as opposed to with each handler method invocation. Therefore, objects like the DynamoDbEnhancedClient have also been refactored to a BaseRideLogHandler superclass. This base class also provides a few helper methods to generate APIGatewayProxyResponseEvent return objects.
public class CreateRideLogHandler
extends BaseRideLogHandler {
@Override
public APIGatewayProxyResponseEvent handleRequest(APIGatewayProxyRequestEvent input,
Context context) {
final String requestBody = input.getBody();
RideLog rideLog;
try {
rideLog = objectMapper.readValue(requestBody, RideLog.class);
rideLogsTable.putItem(rideLog);
} catch (JsonProcessingException | DynamoDbException e) {
return createResponse(HttpURLConnection.HTTP_INTERNAL_ERROR, e.getMessage());
}
final Map<String, String> headers = new HashMap<>();
headers.put("Location", String.format("/ridelogs/%s/%s", rideLog.getUserId(),
rideLog.getStartDateTime().format(DateTimeFormatter.ISO_LOCAL_DATE_TIME)));
return createResponse(HttpURLConnection.HTTP_CREATED, headers);
}
}Base Class
public abstract class BaseRideLogHandler
implements RequestHandler<APIGatewayProxyRequestEvent, APIGatewayProxyResponseEvent> {
private final DynamoDbEnhancedClient enhancedClient = DynamoDbEnhancedClient.create();
protected final DynamoDbTable<RideLog> rideLogsTable =
enhancedClient.table("RideLogs", TableSchema.fromBean(RideLog.class));
protected final ObjectMapper objectMapper = new ObjectMapper();
@Override
public abstract APIGatewayProxyResponseEvent handleRequest(APIGatewayProxyRequestEvent input,
Context context);
protected APIGatewayProxyResponseEvent createResponse(int statusCode, String body) {
return new APIGatewayProxyResponseEvent()
.withStatusCode(statusCode)
.withBody(body);
}
protected APIGatewayProxyResponseEvent createResponse(int statusCode, String body, Map<String, String> headers) {
return new APIGatewayProxyResponseEvent()
.withStatusCode(statusCode)
.withHeaders(headers)
.withBody(body);
}
protected APIGatewayProxyResponseEvent createResponse(int statusCode, Map<String, String> headers) {
return new APIGatewayProxyResponseEvent()
.withStatusCode(statusCode)
.withHeaders(headers);
}
}IAM Permissions
Another change of note is the addition of an IAM policy to our Lambda function declarations in the SAM template. Because the Lambda needs to save data to the DynamoDB table, we need to grant the appropriate permissions to allow this access. We accomplish this by specifying the DynamoDBWritePolicy and associating it with the DynamoDB table, as seen at the bottom of the snippet below.
Note: the Policies item is part of the Properties level for the CreateRideLogHandlerFunction resource.
Resources:
CreateRideLogHandlerFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: RideLog-Lambda-Functions
Handler: dev.ericrybarczyk.ridelog.CreateRideLogHandler::handleRequest
Events:
RideLogs:
Type: Api
Properties:
Path: /ridelogs
Method: Post
# allow this Lambda function to write to the DynamoDB table
Policies:
- DynamoDBWritePolicy:
TableName: !Ref RideLogTable
The write policy chosen here is consistent with a ‘least privilege’ permissions approach. This Lambda function only writes data, it does not read or delete data. Therefore only write permission is needed, as opposed to read or complete CRUD policy options.
If you omit this policy, you are likely to find an error in CloudWatch similar to the example below.
User: arn:aws:sts::1234567890:
assumed-role/ridelogs-CreateRideLogHandlerFunctionRole-10RF4NWDPILZJ/
ridelogs-CreateRideLogHandlerFunction-dxXnIQefA4ct
is not authorized to perform: dynamodb:PutItem
on resource: arn:aws:dynamodb:us-east-1:1234567890:table/RideLogs
(Service: DynamoDb,
Status Code: 400,
Request ID: UBFN9ASUAGKQ6R6PJVV4KQNSO5AEMVJF66QCMA7E52H203E77AJG)
Data Retrieval Functions
Returning data back to a client obviously involves GET requests and reading data from DynamoDB from additional Lambda functions. The GetRideLogHandler function uses a DynamoDB Key which correlates to the composite primary key we defined earlier, using both a partition key and a sort key.
public class GetRideLogHandler extends BaseRideLogHandler {
@Override
public APIGatewayProxyResponseEvent handleRequest(APIGatewayProxyRequestEvent input,
Context context) {
final Map<String, String> pathParameters = input.getPathParameters();
final String userId = pathParameters.get("userId");
final String startDateTime = pathParameters.get("startDateTime");
if (userId == null || startDateTime == null) {
return createResponse(HttpURLConnection.HTTP_BAD_REQUEST, "Required Parameters Missing");
}
Key key = Key.builder()
.partitionValue(userId)
.sortValue(startDateTime)
.build();
try {
final RideLog item = rideLogsTable.getItem(key);
if (item == null) {
return createResponse(HttpURLConnection.HTTP_NOT_FOUND, "Requested RideLog Not Found");
}
final String jsonRideLog = objectMapper.writeValueAsString(item);
return createResponse(HttpURLConnection.HTTP_OK, jsonRideLog);
} catch (JsonProcessingException | DynamoDbException e) {
return createResponse(HttpURLConnection.HTTP_INTERNAL_ERROR, e.getMessage());
}
}
}Obtaining a list of RideLog items for a particular user is a similar exercise, as seen in the code below. The QueryConditional provides the query parameter to the DynamoDB query. The DynamoDB query provides
public class ListRideLogListHandler extends BaseRideLogHandler {
@Override
public APIGatewayProxyResponseEvent handleRequest(APIGatewayProxyRequestEvent input,
Context context) {
final Map<String, String> pathParameters = input.getPathParameters();
final String userId = pathParameters.get("userId");
if (userId == null) {
return createResponse(HttpURLConnection.HTTP_BAD_REQUEST, "Required Parameter Missing");
}
try {
QueryConditional queryConditional = QueryConditional
.keyEqualTo(Key.builder().partitionValue(userId)
.build());
List<RideLogListItem> rideLogs = rideLogsTable.query(r -> r.queryConditional(queryConditional)
.addAttributeToProject("userId")
.addAttributeToProject("startDateTime")
.addAttributeToProject("rideTitle")
.addAttributeToProject("rideLocation")
.scanIndexForward(false))
.items()
.stream()
.map(r -> new RideLogListItem(r.getUserId(), r.getStartDateTime(),
r.getRideTitle(), r.getRideLocation()))
.collect(Collectors.toList());
final String jsonRideLogList = objectMapper.writeValueAsString(rideLogs);
return createResponse(HttpURLConnection.HTTP_OK, jsonRideLogList);
} catch (JsonProcessingException | DynamoDbException e) {
return createResponse(HttpURLConnection.HTTP_INTERNAL_ERROR, e.getMessage());
}
}
}Deployment
Proceed at your own risk. Running the deploy command will create resources in your AWS account, and may result in charges on your AWS bill.
As outlined in the previous article, we can deploy these changes using SAM CLI,
with the command sam deploy –guided. You can omit the –guided parameter when deploying an update, as long as you did not delete
the previous resources and are still using the same deployment settings, including the AWS credentials configured overall in your AWS CLI.
Note that if you began with a fresh deployment in this article, the outputs from the deployment will have included a slightly different auto-generated URL for the API endpoint. You’ll need this URL for manual testing. YOu can also obtain the URL, after the deployment is complete, from the API Gateway admin area in the AWS Console, under Stages, where you will find a, Invoke URL under each of the Prod and Stage areas.
External Test via Postman
With our serverless system deployed, we can run a test using Postman again. Be sure to update the POST body to reflect the changes we made to the data model. Be sure to target the current Invoke URL for the API Gateway endpoint.
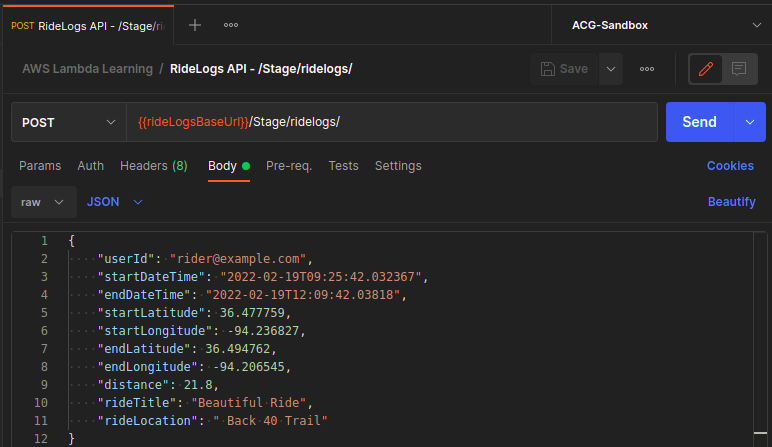
In addition to the successful 201 created response code, we see the expected Location HTTP header.

AWS Console
From the Explore Items link in the DynamoDB area of the AWS Console, you can select a table to view and interact with the items it contains. In our case, we have the RideLogs table and the item we submitted using Postman, as shown below.
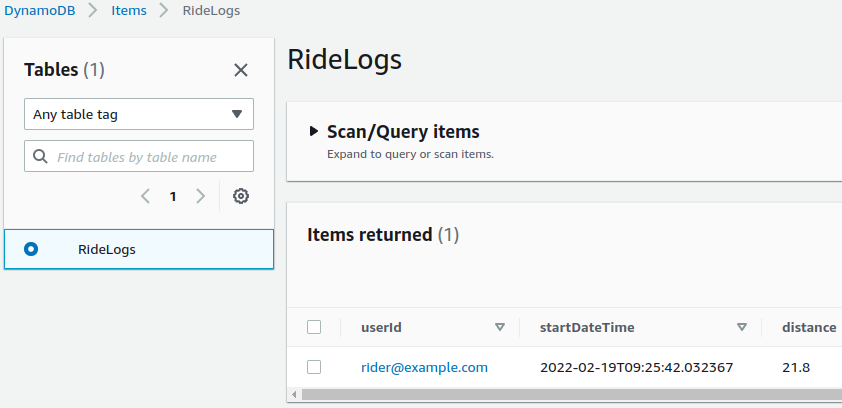
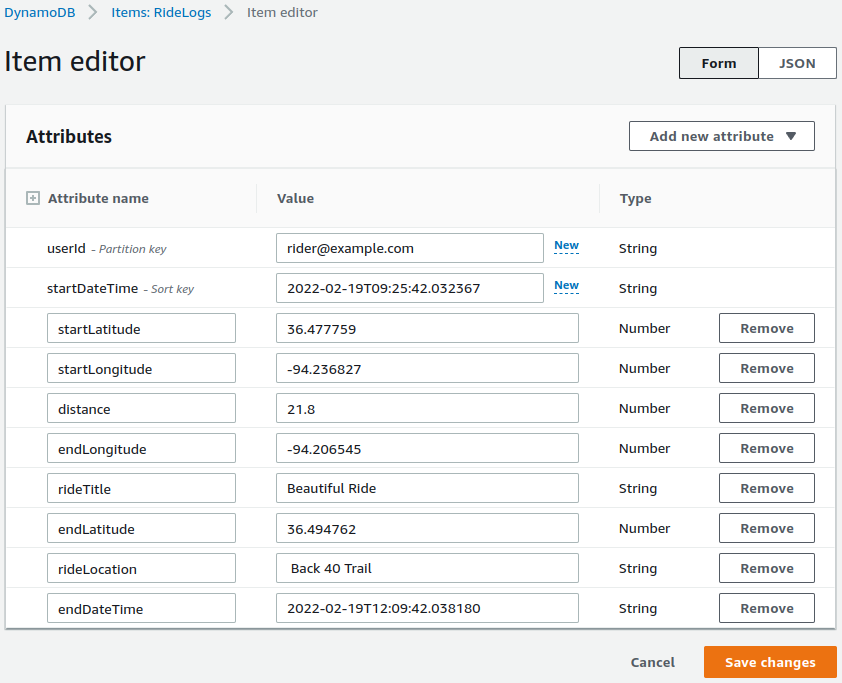
Clicking the primary key field takes us to the Item editor, shown below. There is no need to modify the item, but this view makes it easy to review all the value we submitted.
Cleanup
When you are finished testing and exploring the results, you likely want to terminate all the resources created to minimize any costs.
The SAM tool provides the sam delete command which you can run to delete the entire CloudFormation stack that was created by the deployment action.